이번 포스팅은 빅데이터 플랫폼과 Hadoop Ecosystem에 대해 다뤄보도록 하겠다.
Hadoop 이란 무엇인지?
Hadoop 이란 여러 대의 컴퓨터를 클러스터화하고, 대용량 데이터를 클러스터에서 병렬로 동시에 처리하여 처리 속도를 높이는 것을 목적으로 하는 분산 처리 오픈소스 프레임워크이다.
Hadoop을 구성하는 요소는 다음과 같이 크게 3가지로 분류할 수 있다.
- 분산 파일 시스템 (HDFS)
- 분산 저장을 처리하기 위한 모듈
- 여러 개의 서버를 하나의 서버처럼 묶어서 데이터를 저장
- 리소스 관리자 (YARN)
- 병렬 처리를 위한 클러스터 자원 관리 및 스케줄링 담당
- 분산 데이터 처리 (MapReduce)
- 분산되어 저장된 데이터를 병렬 처리할 수 있게 해주는 분산 처리 모듈
Hadoop Ecosystem 은 또 뭐지?
그러면 Hadoop Ecosystem은 또 무엇을 의미하는 것일까? Hadoop의 코어 프로젝트는 HDFS와 MapReduce이지만, 그 외에도 다양한 서브 프로젝트들이 존재한다. Hadoop Ecosystem은 바로 그 프레임워크를 이루고 있는 다양한 서브 프로젝트들의 모임이라고 볼 수 있다.
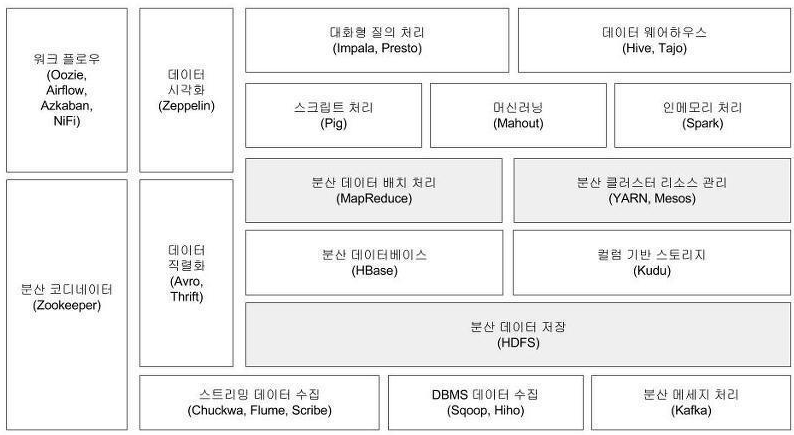
대표적인 Hadoop Ecosystem 프로젝트들을 목적에 맞게 나열해보면 아래과 같다.
- 수집을 위한 프로젝트
- Flume, Sqoop, Kafka
- 데이터 처리를 위한 프로젝트
- 스트림 처리: Kafka, Spark, Flink
- 배치 처리: Spark, MapReduce, Hive
- 데이터 저장을 위한 프로젝트
- HDFS
- HBase: HDFS 상의 column 기반 NoSQL 데이터베이스
- 분산 환경에서 서버 간 상호 조정을 처리해주는 프로젝트
- Zookeeper
- Workflow 관리 도구
- Airflow, Oozie
- 보안 기능을 제공하는 프로젝트
- Ranger
- 메타 데이터를 관리하는 프로젝트
- Atlas
- 분석 및 시각화를 해주는 프로젝트
- Impala, Zeppelin, Superset
- 실시간 데이터 분석 환경 제공: Druid, Pinot
- 머신러닝 알고리즘 제공: Spark, Mahout
그렇다면 이제 Hadoop 클러스터란 무엇인지 알아보고, 이를 구축할 때 고려해야 할 사항들은 무엇이 있는지 살펴보겠다.
여기서 클러스터란 여러 대의 컴퓨터들이 연결되어 하나의 시스템처럼 동작하는 컴퓨터들의 집합(=노드)이라고 할 수 있다.
Hadoop 클러스터는 하나의 마스터 노드(NameNode)와 여러 워커 노드들(DataNode)로 구성되어 있다. 하나의 파일을 여러 개의 블록으로 나눠서 가능한 여러 개의 워커(DataNode)에 저장(default 복제계수 = 3)함으로써, 블록 고장으로 발생하는 문제를 방지할 수 있다.

이러한 Hadoop 클러스터의 규모를 결정하기 위해서는 아래의 사항들에 대해 고민해 볼 필요가 있다.
- 스토리지 용량
- 저장 데이터 크기 예측
- 추가 고려사항: 데이터 포맷, 데이터 압축 여부, 데이터 증가율의 변화
- 복제 전략 결정 >> Default 복제계수 = 3
- 데이터 저장 기간 고려
- 필요한 노드 수 결정
- 저장 데이터 크기 예측
- 데이터 수집 속도
- 데이터 수집 및 처리 속도 예측
- 워크로드에 따른 하드웨어 선정
- CPU
- Memory
- I/O
여기까지 해서 빅데이터 플랫폼과 Hadoop Ecosystem 간의 관계에 대해 살펴보았다.
<Reference>
1. [패스트캠퍼스] 한 번에 끝내는 빅데이터 처리 with Spark&Hadoop 강의
'Data Engineering > Hadoop Ecosystem' 카테고리의 다른 글
| [Airflow Master Class] Docker 및 Airflow 설치 (0) | 2023.08.20 |
|---|---|
| [Airflow Master Class] WSL 설치 & 리눅스(Linux) 기본 명령어 (0) | 2023.08.20 |
| [FastCampus-DE] 4. Hadoop & HDFS (0) | 2022.07.27 |
| [FastCampus-DE] 2. 데이터 파이프라인 (0) | 2022.07.26 |
| [FastCampus-DE] 1. 빅데이터 플랫폼 & 아키텍처 (0) | 2022.07.25 |



