이번 포스팅에서는 서포트 벡터 머신(SVM)을 다뤄보겠다.
머신러닝 모델들 중, 가장 많이 사용하고 성능이 뛰어난 모델이므로 개념을 정확하게 이해해야 할 것 같다.
▶ 선형 SVM 분류
- SVM 분류기(또는 Large Margin Classification)는 클래스 사이에 폭이 가장 넓은 도로를 찾는 것이라고 생각하면 이해하기 쉽다.
- 마진(Margin)이란?
- 두 데이터 군과 결정 경계와 떨어져 있는 정도
- 우리의 목표는 이 margin을 최대화하는 결정 경계(선 또는 면)를 찾아내는 것!!
- 마진(Margin)이란?

- 위 그림을 보면 알 수 있듯이, 도로 바깥쪽에 훈련 샘플을 추가해도 결정 경계에는 영향을 미치지 않는다.
- 또한 결정 경계는 도로 경계에 위치한 샘플. 즉, 서포트 벡터에 의해 결정된다.
- 서포트 벡터란?
- 두 클래스 사이의 경계에 위치한 데이터 포인트들
- 결정 경계를 만드는 데 영향을 미치기 때문에(즉, 결정 경계를 support...) 서포트 벡터라고 부른다.
- 서포트 벡터란?
- SVM은 특성의 스케일에 민감하다.
- 따라서 StandardScaler( )와 같은 스케일링 작업을 수행해주어야 훨씬 더 좋은 결정 경계를 얻을 수 있다.
- 선형 SVM 분류기를 훈련시킬 때, 일반적인 확률적 경사 하강법을 적용한다.
- 비록 속도는 LinearSVC보다 느리지만, 데이터 셋이 너무 크거나 온라인 학습으로 분류 문제를 다룰 때 유용하다.
◆ 하드 마진 분류 / 소프트 마진 분류
- 하드 마진 분류
- 모든 샘플이 도로 바깥 쪽에 올바르게 분류하는 분류기
- <단점>
- 데이터가 선형적으로 구분될 수 있어야 함
- 이상치에 민감

- 소프트 마진 분류
- 도로 폭을 최대한 넓게 유지하는 것과 마진 오류 사이에 적절한 균형을 이루는 분류기
- 사이킷런에서 SVM 모델을 만들 때, C라는 하이퍼 파라미터를 통해 마진 오류를 조정할 수 있다.
- 하이퍼 파라미터 C
- SVM 모델이 과대적합이라면, C를 감소시켜서 모델을 규제할 수 있다.
- 얼마나 많은 데이터 샘플이 다른 클래스에 놓이는 것을 허용하는지 결정
- C가 작을수록 많이 허용, C가 클수록 적게 허용
- 하이퍼 파라미터 C

<참고>
- SVM 분류기는 로지스틱 회귀 분류기와 다르게, 클래스에 대한 확률을 제공하지 않는다.
- 사이킷런의 LinearSVC는 predict_proba( ) 메소드를 제공하지 않지만, SVC 모델은 probability = True로 매개변수를 지정하면 predict_proba( ) 메소드를 제공한다.
- SVC 모델의 probability 매개변수 default 값은 False이다.
- LinearSVC는 규제에 편향을 포함시킨다.
- LinearSVC는 보통의 SVM 구현과 달리 규제에 편향을 포함시키고 있어서, 스케일링 작업을 수행하지 않고 SVC 모델과 비교하면 큰 차이가 난다.
- 때문에 StandardScaler( )을 통해, 훈련 세트에서 평균을 빼서 중앙에 맞춰주어야 한다.
- LinearSVC는 loss 매개변수는 "hinge"로 지정해야 한다.
- LinearSVC는 훈련 샘플보다 특성이 적다면, 성능을 높이기 위해 dual 매개변수를 False로 지정해야 한다.
▶ 비선형 SVM 분류
- 비선형 데이터 셋을 다루는 한 가지 방법으로는 polynomial 특성을 더 추가해주는 방법이 있다.
- 하지만 낮은 차수의 다항식은 과소적합을 발생시키고, 높은 차수의 다항식은 과대적합을 발생시키는 문제점이 있다.
- 이러한 문제점을 보완하기 위해 사용하는 것이 바로 "커널 트릭"이다.
◆ 다항식 커널
- 커널 트릭은 실제로는 특성을 추가하지 않으면서, 다항식 특성을 많이 추가한 것과 동일한 결과를 얻을 수 있다.
- 실제로 어떠한 특성도 추가하지 않으므로 수많은 특성 조합이 생기지 않는다.
- 즉, 수많은 특성 조합을 생성하지 않으므로 모델이 느려지는 것을 방지할 수 있다.

◆ 유사도 특성
- 비선형 분류를 하기 위해서 주어진 데이터를 고차원 특징 공간으로 확장시키는 작업이 필요하다.
- 이를 커널 기법이라고 한다.

- 이를 위한 방법으로 유사도 함수로 계산한 특성을 추가할 수 있다.
- 즉, 각 샘플이 특정 landmark와 얼마나 유사한지를 측정하는 방법이다.
- 다양한 유사도 함수 중, 가장 많이 사용하는 가우시안 방사 기저 함수(RBF)의 식은 다음과 같다.

<참고>
- 가우시안 RBF
- ℓ은 landmark 지점을 의미한다.
- 이 함수의 값은 0(landmark에서 멀리 떨어진 경우)부터 1(landmark와 같은 위치일 경우)까지 변화하며 종 모양으로 나타난다.
- gamma 값은 하나의 데이터 샘플이 영향력을 행사하는 거리를 결정하기 때문에, 규제의 역할을 한다고 볼 수 있다.
- 즉, 가우시안 함수의 표준편차와 관련이 있음을 의미한다.
- gamma 값이 작을수록 폭이 넓은 종 모양이 된다.
- 각 샘플이 넓은 범위에 걸쳐 영향을 주므로, 결정 경계가 부드러워진다.
- 따라서 결정 경계의 곡률을 조정한다고 할 수 있다.
- gamma 값이 클수록 폭이 좁은 종 모양이 된다.
- 각 샘플의 영향 범위가 작아져서, 결정 경계가 더 불규칙해지고 각 샘플을 따라 구불구불하게 휘어진다.
- 따라서 결정 경계의 곡률을 조정한다고 할 수 있다.
- gamma 값이 작을수록 폭이 넓은 종 모양이 된다.
- 즉, 가우시안 함수의 표준편차와 관련이 있음을 의미한다.
<Tips>
- 모델의 복잡도를 조절하려면, gamma와 C를 함께 조정해주는 것이 좋다.
- 여러 가지 커널 중, 가장 먼저 선형 커널을 시도해보는 것이 좋다.
- 선형 커널이 훨씬 더 빠르기 때문이다.
- 특히 훈련 세트가 매우 크거나, 특성 수가 많을 때!!
- 훈련 세트가 너무 크지 않으면, 가우시안 RBF 커널도 시도해볼만 하다.
| 파이썬 클래스 | 시간 복잡도 | 외부 메모리 학습 지원 | 스케일 조정의 필요성 | 커널 트릭 |
| LinearSVC | O(m x n) | X | O | X |
| SGDClassifier | O(m x n) | O | O | X |
| SVC | O(m^2 x n) ~ O(m^3 x n) | X | O | O |
▶ SVM 회귀
-
- 일정한 마진 오류 안에서 두 클래스 간의 도로 폭이 가능한 최대가 되도록 하는 것은 SVM 분류와 동일하다.
- 차이점은 SVM 회귀는 제한된 마진 오류(도로 밖의 샘플) 안에서 도로 안에 가능한 한 많은 샘플이 들어가도록 학습한다는 점이다.
- 도로 폭은 epsilon으로 조절한다.
- SVM을 분류가 아닌 회귀에 적용하려면, 목표를 반대로 설정하면 된다.
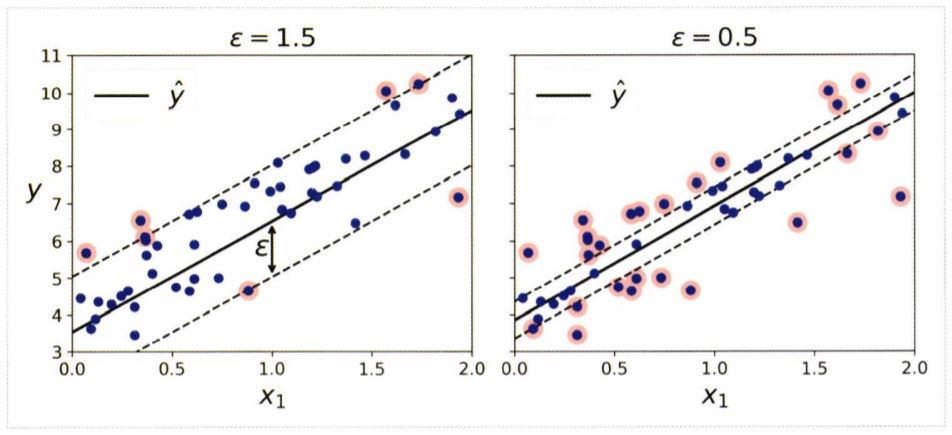
<주의>
- tolerance(허용오차)와 epsilon(도로의 폭)은 다른 것이다!!
- 허용오차는 tol 매개변수, 도로의 폭은 epsilon 매개변수로 지정한다.
- 마진 안에서는 훈련 샘플이 추가되어도 모델의 예측에는 영향이 주지 않는다.
- 즉, epsilon에 민감하지 않은 모델이다.
◆ 비선형 SVM 회귀
- 비선형 회귀 작업을 처리해주려면, 커널 SVM 모델을 사용해야 한다.
- 이해하기 쉽도록, 아래에 2차 다항 커널을 사용한 SVM 회귀 예시 그림을 첨부하였다.

▶ SVM 이론
- 이 부분은 수식이 대부분이고 내용 자체도 어려워서, 추후에 다시 공부할 때 정리해보도록 하겠다.
이번 5장 SVM 부분은 내용이 어려워서, 구글링을 통해 다른 분들이 정리해놓으신 글을 많이 참고했다.
그 중에서, 가장 많은 도움이 되었던 글을 reference로 적어두었다.
★ 참고 자료
서포트 벡터 머신(SVM)의 사용자로서 꼭 알아야할 것들 - 매개변수 C와 gamma
서포트 벡터 머신(SVM)은 딥 러닝이 나온 이후에도 여전히 환영받고 있는 머신러닝(기계학습) 알고리즘이다. 웬만한 상황에서 딥 러닝 못지 않은 성능을 내고, 무엇보다도 가볍기 때문이다. 나��
bskyvision.com
- 핸즈온 머신러닝 2/E 교재
- 파이썬 머신러닝 완벽 가이드 교재
'Data Science > Machine Learning' 카테고리의 다른 글
| [핸즈온 머신러닝 2/E] 7장. 앙상블 학습과 랜덤 포레스트 (0) | 2020.07.27 |
|---|---|
| [핸즈온 머신러닝 2/E] 6장. 결정 트리 (6) | 2020.07.18 |
| [핸즈온 머신러닝 2/E] 4장. 모델 훈련 (0) | 2020.06.27 |
| [핸즈온 머신러닝 2/E] 3장. 분류 (0) | 2020.06.19 |
| [핸즈온 머신러닝 2/E] 2장. 머신러닝 프로젝트 처음부터 끝까지_Part 2 (0) | 2020.06.15 |



