오늘은 교재 4장 "데이터 조작 I: 벡터 기반 처리와 외부 데이터 처리"에 대한 내용을 정리해보겠다.
4장의 양이 꽤나 많으므로, Part 1 과 Part 2로 나눠서 포스팅을 하겠다.
▶ CSV 파일 입출력
read.csv(file, header = FALSE)
- 여기서 header 옵션은 파일의 첫 행을 헤더로 처리할 것인지 여부를 설정하는 것이다.
- header = FALSE 가 default 값이다.
▶ 데이터 프레임의 행과 컬럼 합치기
rbind( ) : 지정한 데이터들을 행으로 취급해서 합친다.
cbind( ) : 지정한 데이터들을 컬럼으로 취급해서 합친다.

▶ apply 계열 함수 --> 요긴하게 써먹을 듯 싶으니, 잘 기억해두자!! ^^
| 함수 | 설명 | 다른 함수와 비교했을 때의 특징 |
| apply() | 배열 또는 행렬에 주어진 함수를 적용한 뒤 그 결과를 벡터, 배열 또는 리스트로 반환 | 배열 또는 행렬에 적용 |
| lapply() | 벡터, 리스트 또는 표현식에 함수를 적용하여 그 결과를 리스트로 반환 | 결과가 리스트 |
| sapply() | lapply 와 유사하지만 결과를 벡터, 행렬 또는 배열로 반환 | 결과가 벡터, 행렬 또는 배열 |
| tapply() | 벡터에 있는 데이터를 특정 기준에 따라 그룹으로 묶은 뒤, 각 그룹마다 주어진 함수를 적용하고 그 결과를 반환 | 데이터를 그룹으로 묶은 뒤, 함수를 적용 |
| mapply() | sapply 의 확장된 버전으로, 여러 개의 벡터 또는 리스트를 인자로 받아 함수에 각 데이터의 첫째 요소들을 적용한 결과, 둘째 요소들을 적용한 결과, 셋째 요소들을 적용한 결과 등을 반환 | 여러 데이터를 함수의 인자로 적용 |
1. apply(X, MARGIN, FUN)

- X : 배열 또는 행렬
- MARGIN = 1 : 행 방향 / MARGIN = 2 : 열 방향
- FUN : 적용할 함수
- 행 또는 열의 합 또는 평균의 계산 → rowSums(), rowMeans(), colSums(), colMeans()
2. lapply(X, FUN)

- X : 벡터, 리스트, 표현식 또는 데이터 프레임
- FUN : 적용할 함수
- lapply( )는 리스트를 반환한다.
- unlist( ) : 리스트 구조를 벡터로 변환할 수 있다.
3. sapply(X, FUN)
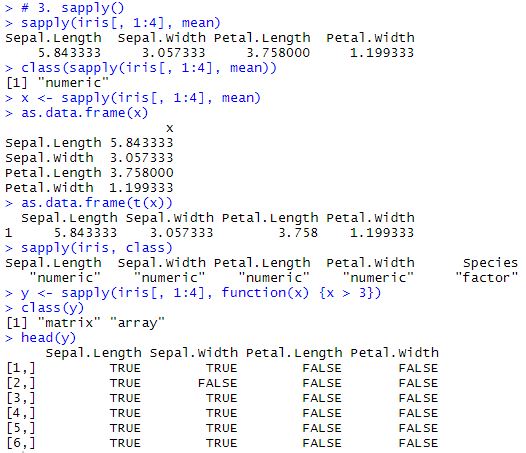
- X : 벡터, 리스트, 표현식 또는 데이터 프레임
- FUN : 적용할 함수
- sapply( )는 벡터를 반환한다.
- sapply( )에 인자로 주어진 함수의 출력이 길이가 1보다 큰 벡터들이라면, sapply( )는 행렬을 반환한다.
- sapply( )는 한 가지 타입만 저장 가능한 데이터 타입인 벡터 또는 행렬을 반환하므로, sapply( )에 인자로 준 함수 FUN의 반환 값에 여러 가지 데이터 타입이 섞여 있으면 안 된다.
4. tapply(X, INDEX, FUN)

- X : 벡터
- INDEX : 데이터를 그룹으로 묶을 색인(index). Factor를 지정해야 하며 factor가 아닌 타입이 지정되면 factor로 형 변환된다.
- FUN : 각 그룹마다 적용할 함수
- tapply( )는 배열을 반환한다.
★ 위의 tapply(m, list(tapply(m, list(c(1, 1, 2, 2, 1, 1, 2, 2), c(1, 1, 1, 1, 2, 2, 2, 2)), sum) 코드에 대한 부연 설명
| male | female | |
| spring | (1, 1) 1 | (1, 2) 5 |
| summer | (1, 1) 2 | (1, 2) 6 |
| fall | (2, 1) 3 | (2, 2) 7 |
| winter | (2, 1) 4 | (2, 2) 8 |
- INDEX를 실제로 지정할 때는 (n, m)에서 n을 먼저 나열한 뒤에 m 값을 나열한다. 즉, 그룹(n1, m1), (n2, m2)는 list(c(n1, n2), c(m1, m2))로 표현한다. 위의 예시는 이러한 방식으로 tapply( )를 사용한 분기별, 성별 합을 구한 예다.
5. mapply(FUN)

- FUN : 실행할 함수
- 위의 R 코드는 다음 세 가지 조합에 대해 호출한 경우이다.
- 아래의 세 가지 조합을 수행하기 위해 rnorm( )을 세 번 호출해도 되지만, mapply( )를 활용하면 훨씬 더 쉽게 호출할 수 있다.
| n | mean | sd |
| 1 | 0 | 1 |
| 2 | 10 | 1 |
| 3 | 100 | 1 |
▶ 데이터를 그룹으로 묶은 후, 함수 호출하기
- 데이터 분석에서는 데이터 전체에 대해 함수를 호출하기보다는 데이터를 그룹별로 나눈 뒤, 각 그룹별로 함수를 호출하는 일이 흔하다.
- 이러한 목적에 특화된 패키지가 바로 "doBY" 패키지이다.
- "doBy" 패키지를 사용하려면, 우선 다음과 같이 패키지를 설치해야 한다.

| 함수 | 특징 |
| summaryBy( ) | 데이터 프레임을 컬럼 값에 따라 그룹으로 묶은 후, 요약 값 계산 |
| orderBy( ) | 지정된 컬럼 값에 따라 데이터 프레임을 정렬 |
| sampleBy( ) | 데이터 프레임을 특정 컬럼 값에 따라 그룹으로 묶은 후, 각 그룹에서 샘플 추출 |
1. summary(object # 요약할 객체) / summaryBy(formula, data)

- 그룹별로 그룹을 특징짓는 통계적 요약 값을 계산하는 함수이다.
- summary( )는 데이터에 대한 간략한 통계 요약을 보여주는 반면, summaryBy( )는 원하는 컬럼의 값을 특정 조건에 따라 요약하는 목적으로 사용한다.
- 위의 예시로 작성한 R 코드는 Sepal.Length와 Sepal.Width를 Species에 따라 살펴보기 위한 코드이다.
- 즉, Sepal.Length와 Sepal.Width를 Species별로 요약한 것이다.
2. order(data, na.last = TRUE, decreasing = FALSE) / orderBy(formula, data)

- order( ) 함수는 주어진 값을 정렬하기 위한 색인(index)을 순서대로 반환한다.
- na.last : NA 값을 정렬한 결과의 어디에 둘 것인지를 제어한다. (default 값은 na.last = TRUE)
- decreasing : 내림차순 여부 (default 값은 FALSE)
- 여러 컬럼을 기준으로 데이터를 정렬하고자 한다면, 해당 컬럼들을 order( )에 나열하면 된다.
- orderBy( )는 order( )와 유사하지만, 정렬할 데이터를 formula로 지정할 수 있다는 점이 편리하다.
- 그러나 실제 R을 사용할 때, orderBy( )보다는 order( )를 더 많이 사용한다.
3. sample(x, size, replace = FALSE) / sampleBy(formula, frac, replace = FALSE, data)

- sample( ) : 주어진 데이터에서 임의로 샘플(표본)을 추출하는 목적으로 사용된다.
- x : 샘플을 뽑을 데이터 벡터
- size : 샘플의 크기
- replace : 복원 추출 여부 (default 값은 FALSE)
- 샘플링은 주어진 데이터를 훈련 데이터와 테스트 데이터로 분리하는 데 유용하게 사용할 수 있다.
- sampleBy( ) : Formula에 따라 데이터를 그룹으로 묶은 후, 샘플을 추출한다.
- frac : 추출할 샘플의 비율이며, 기본 값은 10%
- replace : 복원 추출 여부 (default 값은 FALSE)
- sampleBy( )은 데이터 프레임을 반환한다.
- 모델 성능 평가를 올바르게 하려면 훈련 데이터와 테스트 데이터에 target 값별로 데이터의 수가 균일한 것이 좋은데, 이럴 때 사용하는 것이 바로 sampleBy( )이다.
- 위의 R 코드를 보면, 각 Species별로 5개씩 데이터가 정확히 샘플로 추출된 것을 볼 수 있다.
▶ 데이터 분리 및 병합 --> 데이터 분석에 있어서 매우 중요한 파트!!
1. split(x, f)




- x : 분리할 벡터 또는 데이터 프레임
- f : 분리할 기준을 저장한 factor
- split( )은 리스트를 반환한다.
- 반환 값이 리스트이므로, 위의 R 코드와 같이 lapply( )를 사용하여 iris 종별 Sepal.Length의 평균을 구할 수도 있다.
2. subset(x, subset, select)

- x : 일부를 취할 객체
- subset : 데이터를 취할 것인지 여부
- select : 데이터 프레임의 경우, 선택하고자 하는 컬럼
- subet( )은 조건을 만족하는 데이터를 반환한다.
- subset( )에 select 인자를 지정하면, 특정 컬럼을 선택하거나 제외할 수 있다.
- 특정 컬럼을 제외하고자 한다면, - 를 컬럼 이름 앞에 붙인다.
- select에서 컬럼을 제외하는 방법 외에, names( )와 %in%을 사용하여 제외하는 방법도 있다.
3. merge(x, y, by, all = FALSE)
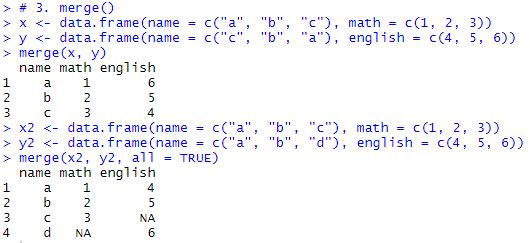
- x : 병합할 데이터 프레임
- y : 병합할 데이터 프레임
- by : 병합 기준으로 사용할 컬럼
- all : 공통된 값이 x, y 중 한쪽에 없을 때의 처리를 뜻한다. (default 값은 FALSE)
- all = FALSE : x, y 모두에 공통된 데이터가 있을 때만 해당 행이 병합 결과에 포함된다.
- all = TRUE : x, y 중 어느 한쪽에 공통된 값을 가지는 행이 없을 때, 해당 쪽을 NA로 채워 병합하여 결과적으로 x, y의 전체 행이 결과에 포함된다.
- 즉, 데이터가 비어 있는 쪽의 값을 NA로 채우면서 전체 데이터를 모두 병합하고 싶다면, all 인자에 TURE를 지정하면 된다.
▶ 데이터 정렬
→ sort(x, decreasing = FALSE, na.last = NA)

- x : 정렬할 벡터
- decreasing : 내림차순 여부 (default 값은 FALSE)
- na.last : NA 값을 정렬할 결과의 어디에 둘 것인지를 제어한다. (default 값은 na.last = NA)
- na.last = TRUE : NA 값을 정렬한 결과의 마지막에 둔다.
- na.last = FALSE : NA 값을 정렬한 값의 처음에 둔다.
- na.last = NA : NA 값을 정렬 결과에서 제외한다.
- sort( )는 값을 정렬한 결과를 반환할 뿐, 인자로 받은 벡터 자체를 변경하지 않는다.
- 즉, 원본 값은 변하지 않고 유지된다.
4장의 내용은 데이터 분석에 있어서 정말 중요한 부분이다. 중요한만큼 잘 숙지해서 추후에 유용하게 사용하도록 하자!! ^^
내일 하루도 힘차게 달려보자!!
★ 참고 자료
- R을 이용한 데이터 처리&분석 실무 교재
'R' 카테고리의 다른 글
| [R을 이용한 데이터 처리&분석 실무] 5장 내용 정리_Part 2 (0) | 2020.06.16 |
|---|---|
| [R을 이용한 데이터 처리&분석 실무] 5장 내용 정리_Part 1 (0) | 2020.06.09 |
| [R을 이용한 데이터 처리&분석 실무] 4장 내용 정리_Part 2 (0) | 2020.06.03 |
| [R을 이용한 데이터 처리&분석 실무] 1 ~ 3장 내용 정리 (0) | 2020.05.28 |



