이번 포스팅에서는 지난 5장 <Part 1>에 이어서, <Part 2>에 대한 내용들을 포스팅 하겠다.
▶ 데이터 구조의 변형과 요약
◎ reshape2 패키지
- 데이터의 모양을 바꾸거나 그룹별 요약 값을 계산하는 함수들을 담고 있는 패키지
- 변환된 데이터는 측정치를 variable과 value라는 두 컬럼으로 표현하므로, 데이터의 통계치 계산이 편리해진다.
★★★
1. melt(data, id.vars, measure.vars, na.rm = FALSE) → 유용하게 쓰이므로 꼭 기억하자!!
- data : melt할 데이터
- id.vars : 식별자 컬럼들
- measure.vars : 측정치 컬럼들. 이 값이 생략되면 id.vars에 해당하지 않는 모든 컬럼이 측정치 컬럼으로 취급된다.
- na.rm = FALSE : NA인 행을 결과에 포함시킬지 여부. FALSE는 NA를 제거하지 않음을 뜻한다.
- 반환 값은 데이터 프레임이다.
- 여러 컬럼으로 구성된 데이터를 데이터 식별자(id), 측정 변수(variable), 측정값(value)이라는 3개의 컬럼으로 변환한다.
- 만약 한 데이터에 대해 다수의 측정 변수(variable)와 측정값(value)이 있다면, 이들은 여러 행으로 표현된다.
- 이렇게 변환된 결과는 variable 컬럼에 측정 대상이 기록되어 있으므로, 각 variable마다 value의 통계값을 계산하는 것이 편리하다.

- 위의 R 코드는 1:4 컬럼을 id, 나머지 컬럼들을 측정치(value)로 놓고 melt( ) 변환을 수행하는 코드이다.
- 만약 NA를 포함하는 측정치(value)를 melt( ) 시 제외하려면, na.rm = TRUE를 지정하면 된다.
- 또한 앞서 말했듯이, 각 variable마다 그룹 지어 통계치를 계산하는 작업이 간단해진다.
- 위의 R 코드는 treatment마다 측정 변수(variable)의 평균을 구하는 코드이다.
2. dcast(data, formula, fun.aggregate = NULL)
- data : melt된 데이터
- formula : 변환 포뮬러. "id 변수 ~ variable 변수" 형태로 입력하며, 아무 변수도 지정하지 않으려면 . 을 사용하고 formula에 명시적으로 나열되지 않은 모든 변수를 표현하려면 . . . 을 사용한다.
- fun.aggregate = NULL : 데이터 재구성 시, 여러 행이 한 셀에 모일 경우 사용할 집합 함수
- 반환 값은 데이터 프레임이다.
- 위 R 코드는 melt( ) 후 dcast( )를 사용해서 다시 원 데이터로 변환하는 예를 보여주는 코드이다.
- identical( )은 두 데이터가 완전히 동일한 객체인지를 알려주는 함수이다.
- 이 외에도 dcast( )는 아래와 같이 데이터의 요약 값을 계산하는 기능이 있다.
- 위의 R 코드는 time에 따라 측정 변수(variable)들의 평균값이 어떻게 달라지는지를 보여주는 코드이다.
▶ 데이터 테이블: 더 빠르고 편리한 데이터 프레임
- as.data.table(df)
- df : 데이터 프레임
- 조건을 만족하는 데이터를 색인(index)를 사용하여 빠르게 찾을 수 있으며, 참조를 통한 데이터 갱신을 지원하여 데이터 복사에 따른 비용을 줄인다. (속도 ↑)
- 데이터를 조건에 따라 그룹 지은 뒤, 통계치를 계산하는 작업을 편리하고 빠르게 수행할 수 있다. (연산의 편의성)
- 위의 R 코드와 같이 data.table( )로 데이터 테이블을 직접 생성할 수도 있다.
- 또한 tables( )로 만든 데이터 테이블들의 목록을 열람할 수도 있다.
- 데이터 접근과 그룹 연산
- 아래의 R 코드에서 확인할 수 있듯이, 데이터 테이블의 데이터는 [행, 표현식, 옵션] 형태로 접근한다.

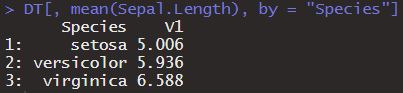
- paste( )와 paste0( ) 함수
- paste(. . . , sep = " ", collapse = NULL)
- . . . : R 객체
- sep = " " : 객체들을 서로 연결할 때 사용하는 구분자
- collapse = NULL : 연결된 객체들을 하나의 문자열로 만들 때 사용하는 구분자
- 벡터를 문자열들로 변환한 후 연결한다.
- 반환 값은 문자열 벡터 또는 문자열이다.
- paste0(. . . , collapse = NULL)
- . . . : R 객체
- collapse = NULL : 연결된 객체들을 하나의 문자열로 만들 때 사용하는 구분자
- 벡터를 문자열들로 변환한 후 연결한다. paste( )와 달리 sep가 항상 빈 문자열이다.
- 반환 값은 문자열 벡터 또는 문자열이다.
- paste(. . . , sep = " ", collapse = NULL)

여기까지 해서 5장 내용 정리를 모두 마치도록 하겠다.
해당 교재의 6장은 그래프에 관한 내용이고, 7장부터는 통계적인 내용이 나온다.
그래프 그리기 및 통계적인 부분들은 실제로 데이터를 다뤄보면서 코드로 구현해보는 것이 실력 향상에 더 도움이 될 것 같다. 때문에 "R을 이용한 데이터 처리 분석&실무" 교재에 대한 포스팅은 여기서 마치도록 하겠다!!
이제부터는 실전이다. 실전! R 데이터 분석!
★ 참고 자료
- R을 이용한 데이터 처리&분석 실무 교재
'R' 카테고리의 다른 글
| [R을 이용한 데이터 처리&분석 실무] 5장 내용 정리_Part 1 (0) | 2020.06.09 |
|---|---|
| [R을 이용한 데이터 처리&분석 실무] 4장 내용 정리_Part 2 (0) | 2020.06.03 |
| [R을 이용한 데이터 처리&분석 실무] 4장 내용 정리_Part 1 (0) | 2020.06.01 |
| [R을 이용한 데이터 처리&분석 실무] 1 ~ 3장 내용 정리 (0) | 2020.05.28 |



