이번 포스팅에서는 "데이터 조작 II : 데이터 처리 및 가공"에 대해서 정리해보겠다.
자, 그럼 시작해보겠다!!
▶ SQL을 사용한 데이터 처리
- sqldf(x)
- x : SQL SELECT 문
- 데이터 프레임에 SQL SELECT 질의를 수행한다. (그냥 SQL과 똑같다고 생각하고 사용하면 된다)
- 반환 값은 데이터 프레임이다.
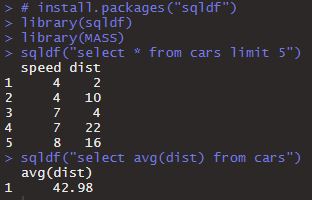
※ iris 데이터를 예시로 설명하면, R과 달리 SQL에서 '.'은 테이블 컬럼명이 될 수 없으므로, Sepal.Length가 아니라 Sepal_Length로 컬럼명을 적어야 한다. 또한 SQL에서 대소문자 구별은 없으므로 Sepal_Length 대신 sepal_length로 적어도 된다.
▶ 분할, 적용, 재조합을 통한 데이터 분석
<plyr 패키지>
- 데이터를 분할하고(split), 분할된 데이터에 특정 함수를 적용한 뒤(apply), 그 결과를 재조합(combine)하는 세 단계로 데이터를 처리하는 함수들을 제공한다.
- 데이터의 분할, 계산, 조합을 한 번에 처리해주어 여러 함수로 처리해야 할 일을 짧은 코드로 대신해준다.
- plyr의 입력은 배열, 데이터 프레임, 리스트가 될 수 있다.
- plyr의 출력도 배열, 데이터 프레임, 리스트가 될 수 있으며 아무런 결과도 출력하지 않을 수도 있다.
{adl} {adl_} ply
입력 데이터 타입 출력 데이터 타입
| 문자 | 용도 | 의미 |
| a | 입력, 출력 | 배열 |
| d | 입력, 출력 | 데이터 프레임 |
| l | 입력, 출력 | 리스트 |
| _ | 출력 | 아무런 출력도 없음 |
1. adply(.data, .margins, .fun = NULL)
- .data : 행렬, 배열, 또는 데이터 프레임
- .margins : 함수를 적용할 방향으로, 1 (행 방향), 2 (컬럼 방향) 또는 c(1, 2) (행과 컬럼 모두의 방향)을 지정할 수 있다.
- .fun = NULL : .margins 방향으로 잘려진 데이터에 적용할 함수
- 배열을 분할하고 함수를 적용한 뒤, 결과를 데이터 프레임으로 반환한다.
- adply( )와 유사한 함수인 apply( )는 행 방향으로 처리할 때, 각 컬럼에 서로 다른 데이터 타입이 섞여 있다면 예상치 못한 타입 변환이 발생할 수 있다.
- 반면, adply( )를 사용하면 위와 같은 예상치 못한 타입 변환을 피할 수 있다.

- 위의 R 코드는 데이터 프레임의 각 행을 보면서 Sepal.Length가 5.0 이상이고, Species가 'setosa' 인지 여부를 확인한 다음, 그 결과를 새로운 컬럼 sepal_ge_5_setosa에 기록하는 예다.
- 최종 반환 값이 데이터 프레임인 경우, 위처럼 함수의 반환 값을 데이터 프레임으로 하는 것이 안전하다.
- 또한 데이터 프레임을 반환할 경우, 위와 같이 계산 값을 저장한 칼럼명을 적절히 지정할 수 있다.
2. ddply(.data, .variables, .fun = NULL)
- .data : 행렬, 배열 또는 데이터 프레임
- .variables : 데이터를 그룹 지을 변수명
- .fun = NULL : 데이터에 적용할 함수
- 데이터 프레임을 분할하고 함수를 적용한 뒤, 결과를 데이터 프레임으로 반환한다.
- adply( )는 행 또는 컬럼 단위로 함수를 적용하는 반면, ddply( )는 .variables에 나열한 컬럼에 따라 데이터를 나눈 뒤 함수를 적용한다.

- 위의 첫 번째 R 코드는 Species와 Sepa.Length가 5.0 보다 큰지 여부 두 가지 조건으로 데이터를 그룹 지은 뒤, 각 그룹마다 Sepal.Width의 평균을 계산한 예다.
- 두 번째, 세 번째 R 코드는 baseball 데이터를 활용하여, 각 선수 별로 데이터를 그룹 짓기 위해 .(id)를 사용하고, 분할된 각 그룹마다 g의 평균을 계산한 예다.
- 즉, 선수마다의 평균 게임 수를 계산한 것이다.
▶ 그룹마다 연산을 쉽게 수행하기
◎ transform(_data, . . .)
- _data : 변환할 객체
- . . . : 태그 = 값 형태의 인자들
- 데이터 프레임 _data에 . . . 에 지정한 연산을 수행한 뒤, 그 결과를 저장한 새로운 컬럼을 추가한 데이터 프레임을 반환한다.

- 위 R 코드는 데이터를 선수 id로 분할하여 그룹 지은 뒤, 각 그룹에서 year의 최솟값과 현재 행의 year 값의 차이를 cyear에 저장한 예다.
◎ mutate(.data, . . .)
- .data : 변환할 데이터 프레임
- . . . : 새로운 컬럼 정의. 컬럼명 = 값 형식
- 반환 값은 변환된 결과다.
- 컬럼명 = 값 형태로 지정된 연산이 여러 개 있을 때, 앞서의 연산 결과를 뒤에 나오는 연산에서 참조할 수 있다.

◎ summarise(.data, . . .)
- .data : 요약할 데이터 프레임
- . . . : 변수 = 값 형태의 인자들
- 데이터의 요약 정보를 만드는 데 사용하는 함수이다.
- . . . 에 지정된 그룹마다의 요약을 수행한 뒤, 그 결과를 저장한 새로운 컬럼이 추가된 데이터 프레임을 반환한다.

- 만약 여러 요약 값을 구하고 싶다면, 위의 R 코드처럼 요약 값 계산을 계속 나열하면 된다.
◎ subset(x, subset) 또는 subset(x, subset, select)
- x : 일부를 취할 데이터
- subset : 데이터를 선택할지 여부를 지정한 논리값 벡터
- select : 선택할 컬럼의 벡터. 제외할 컬럼은 '-'를 붙여서 표시
- 벡터, 행렬, 데이터 프레임의 일부를 반환한다.
- 즉, 각 분할별로 데이터를 추출하는 데 사용한다.
- 아래의 R 코드와 같이 조건을 지정하면, 그룹별로 조건을 만족하는 행만 추출할 수도 있다.

3. mdply(.data, .fun)
- .data : 인자로 사용할 행렬 또는 데이터 프레임
- .fun : 호출할 함수
- 배열이나 데이터 프레임에 저장된 인자로 함수를 호출하고, 결과를 데이터 프레임으로 반환한다.

- 위의 R 코드는 mdply( )를 사용하여 데이터 프레임의 각 행을 rnorm( ) 함수의 mean, sd에 대한 인자로 넘겨 주어 실행한 뒤, 그 결과를 데이터 프레임으로 모은 예다.
여기까지 해서 5장 <Part 1> 포스팅을 마치도록 하겠다.
★ 참고 자료
- R을 이용한 데이터 처리&분석 실무 교재
'R' 카테고리의 다른 글
| [R을 이용한 데이터 처리&분석 실무] 5장 내용 정리_Part 2 (0) | 2020.06.16 |
|---|---|
| [R을 이용한 데이터 처리&분석 실무] 4장 내용 정리_Part 2 (0) | 2020.06.03 |
| [R을 이용한 데이터 처리&분석 실무] 4장 내용 정리_Part 1 (0) | 2020.06.01 |
| [R을 이용한 데이터 처리&분석 실무] 1 ~ 3장 내용 정리 (0) | 2020.05.28 |



