※ 2장은 내용이 다소 많아 두 개의 파트(Part 1, Part 2)로 나눠서 포스팅하도록 하겠다.
2장에서는 독자가 부동산 회사에 막 고용된 데이터 과학자라고 가정하고, 하나의 예제 프로젝트를 처음부터 끝까지 진행해보는 과정을 설명해놓았다.
독자인 우리가 진행해 볼 프로젝트의 주제는 캘리포니아 인구조사 데이터를 사용해서, 캘리포니아의 주택 가격 모델을 만드는 것이다.
분석에 사용할 캘리포니아 인구조사 데이터에는 인구, 중간 소득, 중간 주택 가격 등 여러 가지 특성들이 있다.
▶ 문제 정의
- 어떤 문제를 해결하기에 앞서, 문제를 정의하는 것은 굉장히 중요하다.
먼저 Jupyter Notebook에서 분석에 사용할 데이터를 확인해보면 다음과 같다.


자, 그럼 이제 질문 몇 가지를 하겠다.
우리가 해결하고자 하는 문제를 어떠한 식으로 진행해 볼 수 있을까에 대한 질문으로, 다음과 같다.
1. 지도 학습, 비지도 학습, 강화 학습 중 어떠한 학습 방법을 사용해야 하는지?
2. 이 문제가 분류 문제인지 회귀 문제인지, 그것도 아니면 다른 작업을 수행해주어야 하는지?
고민을 해보았는가? 그렇다면 이제 정답을 발표하겠다.
1. Target 변수(median_house_value)가 존재하기 때문에 지도 학습으로 분류할 수 있겠다.
2. 주택 가격이라는 "값"을 예측해야 하므로, 분류 문제가 아닌 회귀 문제이다.
- 추가적으로 예측에 사용할 특성(feature)이 여러 개(구역의 인구, 중간 소득 등...)이므로 다중 회귀 문제라고 할 수 있으며, 각 구역마다 하나의 값을 예측하는 단변량 회귀(targt 변수가 1개) 문제라고 할 수 있다.
- 만약 구역마다 여러 값을 예측한다면 이 문제는 다변량 회귀(target 변수가 2개 이상) 문제로 볼 수 있겠다.
▶ 성능 측정 지표 선택
- 우리가 현재 직면하고 있는 문제는 회귀 문제이다.
- 회귀 문제의 전형적인 성능 지표는 평균 제곱근 오차(RMSE; Root Mean Square Error)이다.
- 오차가 커질수록 이 값은 더욱 커지므로, 예측에 얼마나 많은 오류가 있는지에 대한 지표로 사용한다.
- 그러나 RMSE는 이상치에 민감하다.

- 회귀 문제에서는 일반적으로 앞서 설명한 RMSE를 많이 사용하지만, 경우에 따라 다른 함수를 사용할 수도 있다.
- 예를 들어, 이상치가 많은 경우에는 RMSE 대신 평균 절대 오차(MAE; Mean Absolute Deviation)를 고려해 볼 수 있다.
- MAE는 RMSE보다 이상치에 덜 민감하다.

<참고>
- m : 데이터 세트에 있는 샘플 수
- x^(i) : 데이터 세트에 있는 i 번째 샘플(레이블은 제외)의 전체 특성 값의 벡터
- y^(i) : 데이터 세트에 있는 i 번째 샘플의 레이블
- X : 데이터 세트에 있는 모든 샘플의 모든 특성값(레이블 제외)을 포함하는 행렬
- h : 시스템의 예측 함수(가설이라고도 함)
- h(x^(i)) : y_hat이라고도 하며, 하나의 샘플 특성 벡터 x^(i)에 대한 예측값을 의미
※ 일반적으로 벡터를 나타낼 때는 x^(i)와 같이 굵은 소문자, 행렬을 나타낼 때는 X와 같이 굵은 대문자를 사용한다.
▶ 가정 검사
- 문제 정의와 성능 측정 지표까지 선택을 완료했다면, 마지막으로 지금까지 만든 가정을 나열하고 (팀원들과 함께) 검사해보는 과정을 거치는 것이 좋다.
- 이 과정은 분석 방향을 제대로 설정했는지 다시 한 번 확인함으로써, 심각한 문제를 사전에 발견하고 처리해주기 위해 거치는 작업이라고 보면 되겠다.
여기까지 해서 본격적으로 코딩을 시작하기 전까지의 작업들은 모두 수행해주었다.
이제 코딩을 통해 머신러닝 프로젝트를 수행해주면 된다.
하지만 이번 챕터의 핵심 내용이 머신러닝 프로젝트를 처음부터 끝까지 경험해보는 것이기 때문에, 코딩에 치우친 설명보다는 머신러닝 프로젝트가 흘러가는 전체적인 흐름에 대해서 설명을 할 것이다.
이 점을 참고해서 글을 읽어주기를 바란다.
자, 그럼 시작해보겠다!! ^^
▶ 데이터 가져오기
- 가장 먼저 해야될 일은 당연히 우리가 분석에 사용할 데이터가 어떻게 생겼는지 확인해주는 작업이다.
- 앞에서 한 번 보여줬지만, 분석에 사용될 데이터 세트를 다시 한 번 확인해보겠다.
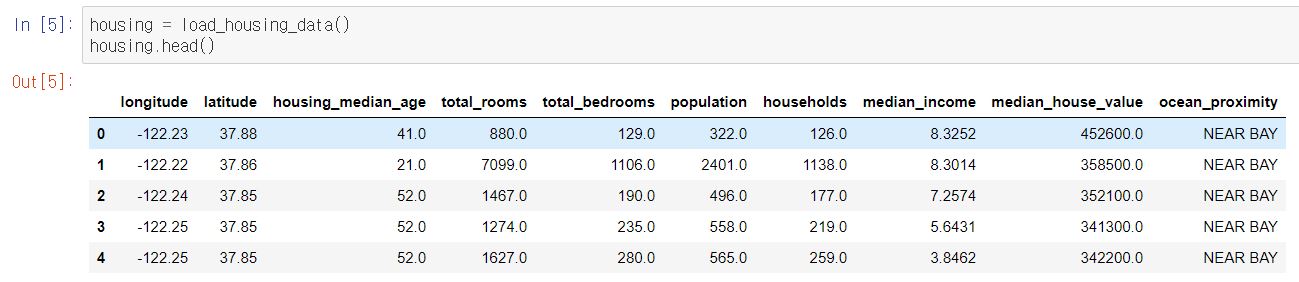
- 데이터 세트에는 20,640개의 샘플이 들어있으며 특성(feature)은 총 10개이다.
- 위를 통해 total_bedrooms 특성은 207개의 Null 값이 존재한다는 사실을 알 수 있다.
- 또한 10개의 특성(feature) 중, 9개가 숫자형(float형)이며 1개가 문자형(object형)이다.
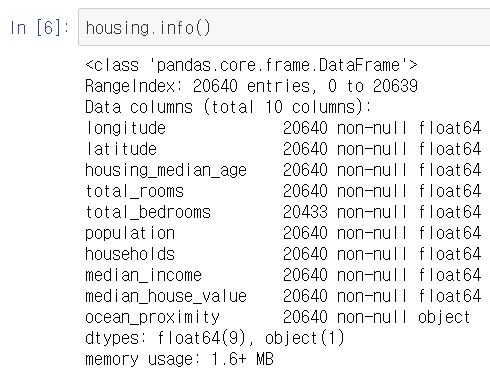
- 이제 describe( ) 메소드를 사용해서, 숫자형 특성의 요약 정보를 확인해봐야 한다.
- 다음으로 데이터의 형태를 확인해보기 위해, 모든 숫자형 특성(feature)들에 대한 히스토그램을 그려본다.
- 히스토그램의 x축은 숫자형 특성을 나타내고, y축은 해당 특성의 값(count)을 나타낸다.
- 히스토그램을 통해 해당 특성(feature)이 어떤 분포를 보이는지 확인해 볼 수 있으며, 분포가 너무 치우친 경우에는 로그 변환을 수행해줄 수 도 있다. (즉, feature scaling, normalization 등과 같은 작업들을 수행)

- 다음으로 테스트 데이터 세트를 만들어준다.
- 일반적으로 전체 데이터 세트의 20%를 테스트 데이터 세트로 사용한다.
- 데이터 세트가 매우 크면, 20% 보다 적게 사용할 수도 있다.
- 여기서 주의할 부분은 여러 번 반복 실행해도 동일한 테스트 데이터 세트가 생성되게끔 해주어야 한다는 것이다.
- 사이킷런은 데이터 세트를 훈련 데이터 세트와 테스트 데이터 세트로 쉽게 나눠주는 train_test_split 함수를 제공한다.
- test_size : 테스트 데이터 세트의 크기를 지정
- random_state : 난수 초깃값을 지정 (여러 번 데이터 셋이 갱신되도 테스트 세트가 동일하게 유지됨)

- 또한 테스트 데이터 세트를 만들 때, 테스트 데이터 세트를 절대 들여다보면 안 된다!!
- 테스트 데이터 세트에서 겉으로 드러난 어떤 패턴에 속아 특정 머신러닝 모델을 선택하게 될 수 있기 때문이다. (데이터 스누핑 편향)
- 하지만 데이터 세트가 충분히 크지 않은 경우, 위처럼 단순 무작위 샘플링을 사용해서 훈련 데이터 세트와 테스트 데이터 세트를 만들어주면 샘플링 편향이 생길 가능성이 높다.
- 이를 해결하기 위한 방법으로는 계층적 샘플링 방법이 있다. (층화 추출법이라고도 한다)
- 모집단을 비슷한 성질을 갖는 2개 이상의 동질적인 층으로 구분하고, 각 층으로부터 단순 무작위 추출 방법을 적용하여 표본을 추출하는 방법이다.
- 표본 크기가 크지 않아도 모집단의 대표성이 잘 보장된다는 장점이 있다.
- 즉, 데이터 세트의 특성 분포를 고르게 해준다.
- ex) 전체 10,000명 중 남자가 9,000명일 때, 500명을 무작위로 추출하면 여자가 뽑힐 확률이 매우 낮아진다. 그러므로 20:1의 남녀비율로 층화시킨 후, 각 층으로부터 단순 무작위 추출을 하면 남자 450명과 여자 50명의 표본을 추출할 수 있다.
- ex) 고등학교 학생들을 1학년 층, 2학년 층, 3학년 층으로 구분하고, 각각의 층으로부터 단순 무작위 추출을 한다. 이렇게 하면 각 학년들끼리만 있으니까 집단 내에서는 동질적이고, 학년이라는 특성이 서로 다르므로 집단 간 차이가 이질적이다.
- 다음과 같이 사이킷런의 StratifiedShuffleSplit( )을 사용하면 계층 샘플링을 수행할 수 있다.

<데이터 세트 분할 작업에 대한 내용 요약>

▶ 데이터 이해를 위한 탐색과 시각화
- 훈련 데이터 세트와 테스트 데이터 세트를 분리했다면, 이제 훈련 데이터 세트에 대한 데이터 탐색 및 시각화 과정이 수행되어야 한다.
- 먼저 표준 상관계수(피어슨 상관계수)를 사용하면, 특성 간 상관관계를 수치화된 값으로 확인할 수 있다.
- 상관계수는 -1부터 1까지 가질 수 있다. (즉, 범위가 -1부터 1까지라는 의미)
- 1 에 가까우면 강한 양의 상관관계를 가진다는 의미이고, -1 에 가까우면 강한 음의 상관관계를 가진다는 의미이다.
- 상관계수가 0 에 가까우면, 선형적인 상관관계가 없다는 의미이지 상관관계가 아예 없다는 의미가 아니다!!
- 아래의 결과를 살펴보면, 중간 주택 가격(median_house_value)은 중간 소득(median_income)과 양의 상관관계를 갖는다는 것을 알 수 있다.
- 즉, 중간 소득이 올라갈 때 중간 주택 가격이 증가하는 경향이 있다는 것을 의미한다.

- 또한 아래와 같이, 산점도 행렬(숫자형 특성 사이에 산점도 및 히스토그램)를 사용해서 특성 간 상관관계를 확인해 볼 수도 있다.

- 앞서 우리는 머신러닝 알고리즘에 데이터를 주입하기 전에 다양한 데이터 전처리 과정을 수행해주었다.
- 데이터의 형태는 어떠한지, 어떠한 특성들이 있고 특성들의 분포 및 상관관계는 어떠한지, 테스트 데이터 세트를 어느 정도로 설정할지 등등...
- 여기에 추가적으로 다음과 같이 여러 특성의 조합을 시도해 볼 수도 있다.
- 전체 방 개수(total_rooms)는 얼마나 많은 가구 수가 있는지 모른다면 그다지 유용하지 않다.
- 진짜 필요한 것은 가구당 방 개수(rooms_per_household)이다.
- 전체 침대 개수(total_bedrooms)도 그 자체로는 유용하지 않다.
- 즉, 방당 침대 개수(bedrooms_per_room)를 확인해보아야 한다.
- 또한 가구당 인원(population_per_household)도 괜찮은 특성 조합으로 보인다.
- 결과를 보면, 새로 만들어준 방당 침대 개수(bedrooms_per_room) 특성은 전체 방 개수(total_rooms)나 침대 개수(total_bedrooms)보다 중간 주택 가격(median_house_value)과의 상관관계가 훨씬 높은 것을 확인할 수 있다.
- 전체 방 개수(total_rooms)는 얼마나 많은 가구 수가 있는지 모른다면 그다지 유용하지 않다.
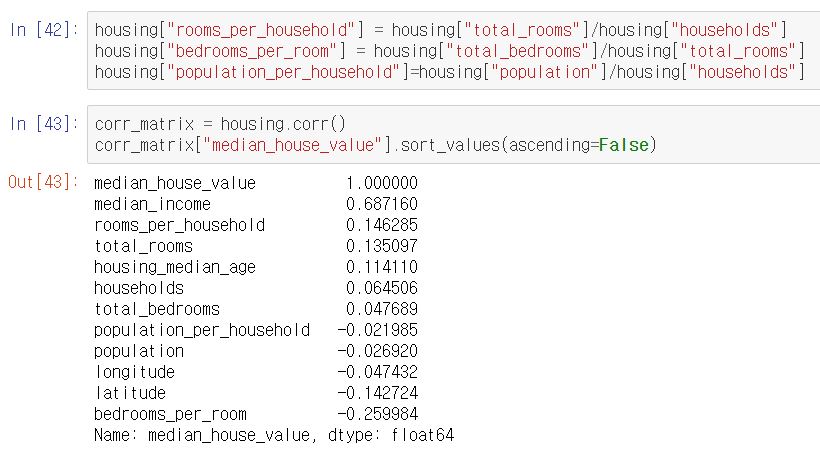
- 위와 같이 데이터를 탐색하고 처리해주는 과정은 정말로 중요하다. 정확하게 데이터에 대해 파악을 하고 있어야 좋은 결과물을 만들어 낼 수 있기 때문이다. 데이터를 정확하게 파악하고 전처리 해주는 것이 예측 모델의 성능을 올리는 지름길임을 반드시 명심하자!!
여기까지 해서 2장 <Part 1>에 대한 포스팅은 마치도록 하겠다. <Part 2>에서는 feature engineering과 모델 학습/평가/예측에 대한 내용을 다뤄볼 것이다.
★ 참고 자료
- 핸즈온 머신러닝 2/E 교재
- 파이썬 머신러닝 완벽 가이드 교재
'Data Science > Machine Learning' 카테고리의 다른 글
| [핸즈온 머신러닝 2/E] 5장. 서포트 벡터 머신 (0) | 2020.07.08 |
|---|---|
| [핸즈온 머신러닝 2/E] 4장. 모델 훈련 (0) | 2020.06.27 |
| [핸즈온 머신러닝 2/E] 3장. 분류 (0) | 2020.06.19 |
| [핸즈온 머신러닝 2/E] 2장. 머신러닝 프로젝트 처음부터 끝까지_Part 2 (0) | 2020.06.15 |
| [핸즈온 머신러닝 2/E] 1장. 한 눈에 보는 머신러닝 (0) | 2020.05.30 |



