이번 포스팅에서는 지난 번 2장 <Part 1>에 이어서 <Part 2>를 진행해도록 하겠다.
자, 그럼 시작해보겠다!!
▶ 머신러닝 알고리즘을 위한 데이터 준비(Feature Engineering)
- 본격적인 시작에 앞서, 다음과 같이 strat_train_set( ) 함수를 사용하여 훈련 데이터 세트를 target 변수가 제외된 데이터 세트(feature들만 존재)과 target 변수만 있는 데이터 세트로 분리하겠다.

◆ 데이터 정제
- Null 값 처리
- 해당 구역을 제거하는 방법
- dropna( ) 사용
- 전체 특성(feature)을 삭제하는 방법
- drop( ) 사용
- 다른 값으로 대체하는 방법(0, 평균값, 중앙값 등)
- fillna( ) 사용
- 교재에서는 누락된 값들을 중앙값으로 대체해주었다.
- 해당 구역을 제거하는 방법
- 범주형 특성 처리
- 아래와 같이 우리가 분석할 데이터 셋에도 범주형 특성(ocean_proximity)이 존재한다.

- 대부분의 머신러닝 알고리즘은 숫자를 다루므로, 범주형 특성인 ocean_proximity를 숫자로 변환해주는 작업을 수행해주겠다.
- 이러한 경우 사용하는 것이 바로 "One-Hot Encoding(원-핫 인코딩)" 방법이다.
- Feature 값의 유형에 따라 새로운 feature를 추가해 고유 값에 해당하는 컬럼에만 1 을 표시하고, 나머지 컬럼에는 0 을 표시하는 방법이다.
- 즉, 한 특성만 1이고 나머지는 0으로 넣어주는 인코딩 방법이다.
- 원-핫 인코딩을 통해 생성된 새로운 특성을 더미(dummy) 특성이라고도 한다.


<One-Hot Encoding 예시>
- 아래의 예시를 보면, 원-핫 인코딩이 어떤 방법인지 쉽게 이해할 수 있을 것이다.

- 특성 스케일링(Feature Scaling)
- 머신러닝 알고리즘은 숫자형 특성들의 스케일이 많이 다르면 잘 작동하지 않는다.
- 스케일이 많이 다른 경우, 모든 특성들의 범위를 같도록 만들어줘야 하는데, min-max 스케일링과 표준화(standardization)가 널리 사용된다.
1. Min-Max Scaling
- 데이터에서 최솟값을 뺀 후, 최댓값과 최솟값의 차이로 나눠준다.
- 0 ~ 1 범위에 들도록 값을 이동하고 scale을 조정하는 방법이다.

2. 표준화(Standardization)
- 데이터에서 평균을 뺀 후, 표준편차로 나누어 분산이 1이 되도록 해준다. (즉, 표준 정규 분포를 따르게 된다)
- 이상치에 덜 민감하다.

<참고>
◎ 변환 파이프라인
앞서 수행해 준 변환 작업들은 정확한 순서대로 실행이 되어야 한다. 하지만 변환 단계가 많으면 헷갈릴 수 있는데, 이를 위해 사이킷런에서는 연속된 변환들을 순서대로 처리할 수 있도록 도와주는 Pipeline 클래스를 제공한다.

또한 사이킷런에서는 각 열마다 적절한 변환을 적용하여 모든 열을 처리할 수 있도록 도와주는 ColumnTransformer 클래스도 제공한다.

▶ 모델 선택과 훈련
- 앞서 수행해 준 작업들은 데이터 전처리 부분에 해당한다.
- 전체적인 흐름에 대해서 간략하게 설명하는 것을 목표로 했기에 디테일한 부분들까지 전처리를 수행해주지는 않았으나, 기본적으로 데이터 전처리 과정은 굉장히 중요하다!! (예측 모델의 성능을 좌지우지 할 정도로...)
- 훈련 데이터 세트에서 훈련하고 평가하기
- 이제 모델을 선택하고 훈련시켜서 평가해주는 작업을 수행해주겠다.
- 우선은 선형 회귀 모델과 결정 트리 모델을 적용시켜보려 한다.
1. 선형 회귀(Linear Regression)
- 선형 회귀 모델을 적용시켜서 RMSE 값과 MAE 값을 도출해보겠다.


- RMSE 값이 약 68628.20 으로 나왔고, MAE 값은 약 49439.90 으로 나왔다.
- 대부분 구역의 중간 주택 가격(median_house_value)은 $120,000에서 $ 265,000 사이이다. 때문에 예측 오차$68,628.20을 좋은 수치라고 볼 수 는 없을 것 같고, 모델이 훈련 데이터 세트에 과소적합(underfitting)되었다고 볼 수 있겠다.
- 이는 모델에 포함된 특성(feature)들이 충분한 정보를 제공하지 못했거나, 모델이 충분히 강력하지 못했기 때문이다.
- 이를 개선하기 위해서는 더욱 강력한 모델을 사용하거나, 모델을 더 좋은 특성(feature)들로만 구성되도록 수정해주어야 한다.
2. 결정 트리(Decision Tree)
- 결정 트리 모델은 선형 회귀 모델보다 더 강력하기 때문에, 복잡한 비선형 관계를 찾을 수 있다.
- 마찬가지로 결정 트리 모델을 사용하여 RMSE 값을 구해보겠다.

- RMSE 값을 보면 0 이라고 나온 것을 확인할 수 있다. (현실에서는 절대 불가능...)
- 그렇다면 정말로 이 모델이 완벽한 모델일까? 그렇지 않다!!
- 이는 모델이 훈련 데이터 세트에 심하게 과대적합(overfitting)하여 발생한 결과라고 볼 수 있다.
- 교차 검증을 사용한 평가
- 위와 같이 과대적합(overfitting)이 발생하는 이유는 테스트 데이터 세트가 데이터 중 일부분으로 고정되어 있기 때문에 발생한다.
- 교차 검증은 데이터 세트의 모든 부분을 사용하여 모델을 검증하고, 테스트 데이터 세트를 하나로 고정하지 않는다.
- 즉, 훈련 데이터 세트의 일부분으로 훈련을 시키고, 다른 일부분으로 모델 검증을 수행해주어야 한다.
- 먼저 전체 데이터 셋을 k개의 subset으로 나누고, k번의 모델 평가를 수행한다. 이때 테스트 데이터 세트를 중복없이 바꾸어가며 평가를 진행한다.
- 다음으로 k개의 평가 지표를 평균내서 최종적으로 모델의 성능을 평가한다.


- 이제 선형 회귀 모델과 결정 트리 모델에 대해서 사이킷런의 k-fold 교차 검증 기능을 사용해보겠다.
- 결과를 살펴보면 결정 트리 모델의 점수가 약 71407.70 이고, 선형 회귀 모델의 점수는 약 69052.46 이다.
- 확실히 결정 트리 모델이 과대적합되어서 선형 회귀 모델보다 성능이 좋지 않다.


3. 랜덤 포레스트 회귀(Random Forest Regressor)
- 추가적으로 랜덤 포레스트 회귀 모델을 하나 더 시도해보겠다.
- 랜덤 포레스트는 여러 개의 결정 트리 모델을 모아서 만든 하나의 모델로, 앙상블 학습을 통해 만들어진 모델이다.
- 랜덤 포레스트에 대한 설명은 7장에서 자세히 할 예정이므로, 우선은 이 정도만 설명하고 넘어가겠다.

- 랜덤 포레스트 모델의 경우, 앞서 본 선형 회귀 모델이나 결정 트리 모델보다는 성능이 더 뛰어난 것 같다.
- 하지만 훈련 데이터 세트에 대한 점수가 검증 데이터 세트에 대한 점수보다 훨씬 낮은 것으로 보아, 여전히 훈련 데이터 세트에 과대적합되어 있음을 알 수 있다.
※ 여러 종류의 머신러닝 알고리즘으로 하이퍼 파라미터 조정에 너무 많은 시간을 들이지 않으면서, 다양한 모델들을 시도해봐야 한다.
▶ 모델 세부 튜닝
- 위 과정을 통해 가능성 있는 모델들을 추렸다면, 이제 해당 모델들을 세부 튜닝해주는 작업을 수행해주어야 한다.
- 우선 단순하게 만족할 만한 하이퍼 파라미터 조합을 찾을 때까지 수동으로 하이퍼 파라미터를 조정해주는 방법이 있다.
- 하지만 이 방법은 경우의 수가 많아질수록 굉장히 많은 시간이 소요된다.
- 때문에 사이킷런의 GridSearchCV를 사용하는 것이 좋다.
- GridSearchCV를 사용하면 탐색하고자 하는 하이퍼 파라미터와 시도해볼 값을 지정하기만 하면 된다.
- 그러면 가능한 모든 하이퍼 파라미터 조합들에 대해서 교차 검증을 사용해서 평가를 수행해준다.
- 이제 랜덤 포레스트 회귀 모델에 대한 최적의 하이퍼 파라미터 조합을 탐색해보겠다.
- 총 18개의 조합을 탐색하고, 각각 다섯 번 모델을 훈련시킨다.
- 즉, 전체 훈련 횟수는 18 x 5 = 90 이 된다.

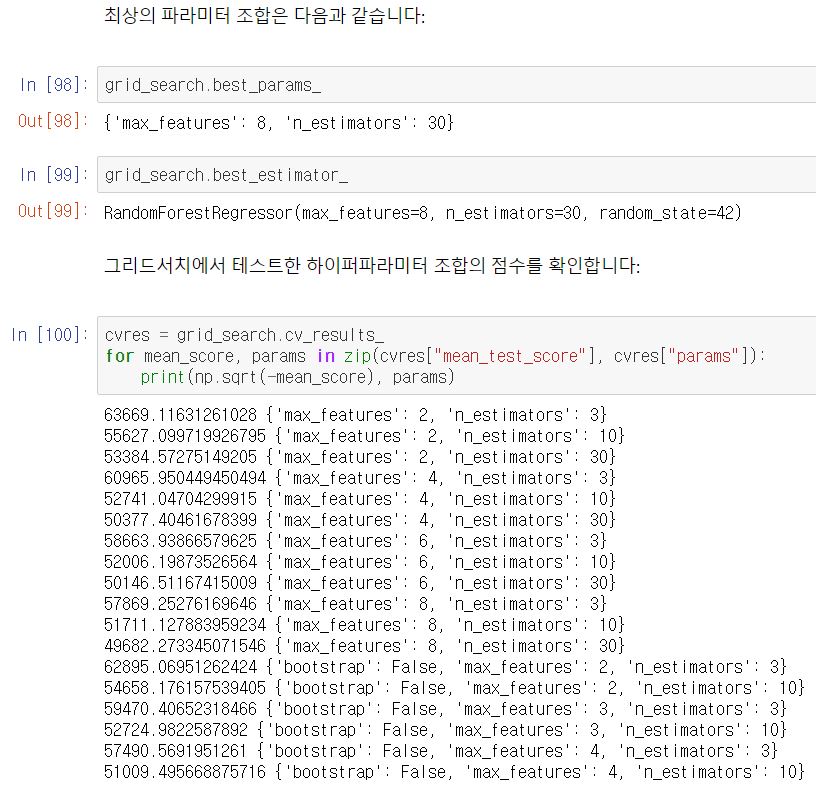
- 결과를 보면, max_features = 8, n_estimators = 30 인 경우의 RMSE 값이 가장 낮음을 알 수 있다.
- 앞서 기본 하이퍼 파라미터로 얻은 RMSE 값인 50182.30 보다 더 낮은 RMSE 값(49682.27)을 얻었다.
<참고> 랜덤 탐색
- GridSearchCV 방법은 비교적 적은 수의 조합을 탐색할 때 사용하기 좋다.
- 만약 하이퍼 파라미터 탐색 공간이 커지면, RandomizedSearchCV를 사용하는 것이 좋다.
- 가능한 모든 조합을 시도하는 대신, 각 반복마다 하이퍼 파라미터에 임의의 수를 대입하여 지정한 횟수만큼 평가하는 방법이다.

▶ 앙상블 방법
- 모델의 그룹(또는 앙상블)이 최상의 단일 모델보다 더 나은 성능을 보여줄 때가 많다.
- 특히 개개의 모델이 각기 다른 형태의 오차를 만든다면, 앙상블 모델을 사용하는 것이 좋다.
- 앙상블에 관한 내용은 7장에서 자세히 다루도록 하겠다.
▶ 최상의 모델과 오차 분석
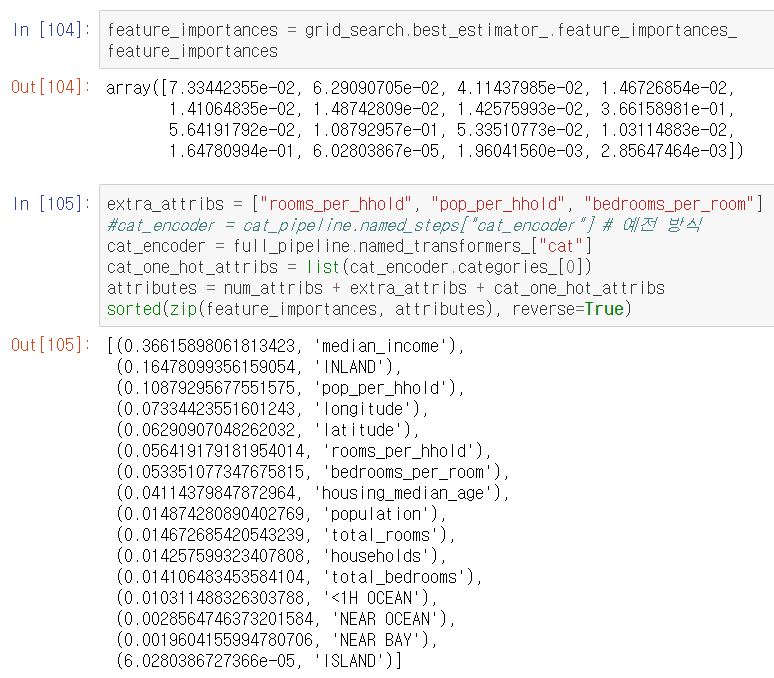
- 랜덤 포레스트 회귀 모델을 사용하면, feature_importances_ 속성을 사용하여 각 특성의 상대적인 중요도를 알 수 있다.
- 결과를 보면, 중간 소득(median_income) 특성의 중요도가 가장 높은 것을 확인할 수 있다.
- 이러한 정보들을 바탕으로 상대적으로 덜 중요한 특성들을 제외할 수 있다.
▶ 테스트 데이터 세트로 최종 모델 평가하기
- 모델에 대한 튜닝을 마치면, 이제 테스트 데이터 세트에 최종 모델을 적용해서 평가를 수행할 차례이다.
- 만들어진 최종 모델을 테스트 데이터 세트에 적용해보도록 하겠다.

- 최종 모델에 대한 RMSE 값이 약 47730.23 으로 나왔다.
- 이 추정값이 얼마나 정확한지 알고 싶다면, 다음과 같이 scipy.stats.t.interval( )을 사용해서 일반화 오차의 (1-alpha)% 신뢰구간을 확인해볼 수도 있다.
※ 신뢰구간이란 해당 구간 내에 실제 모수가 존재할 것으로 예측되는 구간이다.
<신뢰구간에 대한 자세한 설명이 첨부된 링크>
↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓
https://hsm-edu.tistory.com/983
모수추정에서 신뢰구간과 신뢰수준의 진짜 의미
모수추정에서 신뢰구간과 신뢰수준의 진짜 의미 모수 추정에 대한 질문을 하나 받았습니다. 모수추정을 그냥 설명할 수도 있지만, 질문으로 부터 출발하면 이해가 한결 쉬울 것입니다. 질문을
hsm-edu.tistory.com

▶ 론칭, 모니터링, 시스템 유지 보수
- 위에서 수행한 일련의 과정들을 통해 최종 예측 모델을 만들어냈다.
- 하지만 머신러닝 프로젝트를 제품으로 만들고 배포하기 위해서는 다음과 같은 추가 사항이 더 필요하다.
- 모니터링 도구 구축
- 주기적인 모델 학습 자동화
- 다시 말해 만들어낸 모델을 배포한 후에도, 위 과정들을 통해 시스템 유지 및 보수에 힘써야 한다는 것이다.
여기까지 해서 2장 <Part 2>에 대한 내용을 마무리 하도록 하겠다.
★ 참고 자료
- 핸즈온 머신러닝 2/E 교재
- 파이썬 머신러닝 완벽 가이드 교재
'Data Science > Machine Learning' 카테고리의 다른 글
| [핸즈온 머신러닝 2/E] 5장. 서포트 벡터 머신 (0) | 2020.07.08 |
|---|---|
| [핸즈온 머신러닝 2/E] 4장. 모델 훈련 (0) | 2020.06.27 |
| [핸즈온 머신러닝 2/E] 3장. 분류 (0) | 2020.06.19 |
| [핸즈온 머신러닝 2/E] 2장. 머신러닝 프로젝트 처음부터 끝까지_Part 1 (0) | 2020.06.07 |
| [핸즈온 머신러닝 2/E] 1장. 한 눈에 보는 머신러닝 (0) | 2020.05.30 |



