드디어 "핸즈온 머신러닝 2/E" 교재를 Part 1(머신러닝 파트)까지 완독하였다!!
자, 그럼 이제 Part 1의 마지막 챕터인 "9장. 비지도 학습"에 대해서 정리해보도록 하겠다.
▶ 비지도 학습이란?
- 우리가 사용할 수 있는 대부분의 데이터는 레이블이 없다.
- 즉, 정답이 없는 데이터이기 때문에 지도 학습을 사용할 수가 없다.
- 이러한 경우에 사용하는 방법이 바로 "비지도 학습"이다.
- 대표적인 비지도 학습으로는 Clustering(군집 분석)이 있다.
▶ 군집 분석(Clustering)
- 앞서 말했듯이, 군집 분석은 대표적인 비지도 학습이다.
- 주의할 점은 "분류"와 "군집"을 헷갈리면 안 된다는 것이다.
- 아래의 그림을 참고하면, 분류와 군집을 구분할 수 있을 것이라고 생각한다.

- 군집 분석은 다방면에서 활용될 수 있다.
- 고객 분류
- 데이터 분석 → 각 cluster별로 따로 분석!!
- 차원 축소 → 지도 학습 알고리즘을 적용하기 전에 전처리 단계에서 활용 가능!!
- 이상치 탐지
- 준지도 학습 → 레이블이 없는 데이터가 많고, 레이블이 있는 데이터는 적은 경우에 사용
- 검색 엔진
- 이미지 분할 → 이미지를 여러 개의 segment로 분할하는 작업
- Cluster에 대한 보편적인 정의는 따로 없으며, 군집 알고리즘에 따라 다른 종류의 cluster를 감지한다.
◆ K-means 알고리즘
- 이 알고리즘은 각 cluster의 중심을 찾고 가장 가까운 cluster에 샘플을 할당한다.
- 사이킷런의 KMeans 클래스를 사용하면 된다.
- 다만 한 가지 고려해야 할 부분은 알고리즘이 찾을 cluster 개수 k를 직접 지정해주어야 한다는 점이다.
- 적절한 cluster 개수를 지정해주는 것이 쉬운 일이 아니다...

- K-means 알고리즘은 cluster의 크기가 많이 다르면 잘 작동하지 않는다.
- 샘플을 cluster에 할당할 때, centroid까지 거리를 고려해주는 것이 전부이기 때문이다.
- 일반적으로 K-means 알고리즘은 속도가 빠르다.
<참고>
1. 하드 군집
- 각 샘플에 대해 가장 가까운 cluster를 선택하는 것
2. 소프트 군집
- Cluster마다 샘플에 점수를 부여하는 것
- 그렇다면 여기서 말하는 점수란?
- 샘플과 centroid 사이의 거리 (KMeans 클래스의 transform( ) 메소드를 통해 구할 수 있음)
- 유사도 점수
- 그렇다면 여기서 말하는 점수란?
- 고차원 데이터 셋을 저차원으로 변환할 때, 매우 효율적인 비선형 차원 축소 기법이다.
<K-means 알고리즘의 작동 원리>
1. Centroid를 랜덤하게 초기화
2. 샘플에 레이블을 할당
3. Centroid 업데이트
4. 샘플에 다시 레이블을 할당
5. 최적으로 보이는 cluster에 도달할 때까지 위 과정들을 반복!!

<Centroid 초기화 방법>
- 한 가지 방법으로는 다른 군집 알고리즘을 먼저 실행해서 centroid 위치를 근사하게 파악해 볼 수 있다.
- 또 다른 방법으로는 centroid 랜덤 초기화를 다르게 하여 여러 번 알고리즘을 실행하고, 최적의 솔루션을 선택하는 것이다.
- 그렇다면 최적의 솔루션을 어떻게 알 수 있을까?
- 이 때 사용하는 성능 지표가 바로 모델의 이너셔(inertia)이다.
- 모델의 이너셔(inertia)란 각 샘플과 가장 가까운 centroid 사이의 평균 제곱 거리를 의미한다.
- 이너셔(inertia)가 낮을수록 좋은 모델이다.
- 그렇다면 최적의 솔루션을 어떻게 알 수 있을까?
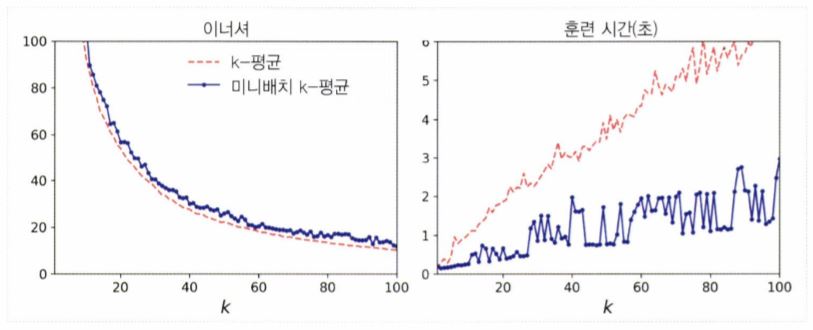
<미니배치 k-means 알고리즘>
- 전체 데이터 셋을 사용해 반복하지 않고, 각 반복마다 미니배치를 사용해서 centroid를 조금씩 이동하는 방법이다.
- 이 알고리즘을 사용하면, 일반적으로 k-means 알고리즘의 속도를 3배에서 4배 정도 높일 수 있다.
- 다만, 이너셔(inertia)는 일반적으로 k-means 알고리즘보다 안 좋다.
- 특히 cluster의 개수가 증가할 때 위와 같은 현상이 발생한다.
- 사이킷런의 MiniBatchKMeans 클래스를 사용하면 된다.
<최적의 cluster 개수 찾기>
- 일반적으로 최적의 cluster 개수(k)를 지정해주는 것은 쉬운 일이 아니다.
- 왜죠? 가장 작은 이너셔(inertia)를 가진 모델을 선택하면 되는 거 아닌가요? → No!!
- Cluster가 늘어날수록 각 샘플은 가까운 centroid에 더 가깝게 된다. 따라서 이너셔(inertia)는 더 작아질 것이다!
- 그러면 우리는 어떻게 최적의 cluster 개수를 찾아서 지정해줄 수 있을까?
- 일반적으로 많이 사용하는 두 가지 방법은 다음과 같다.
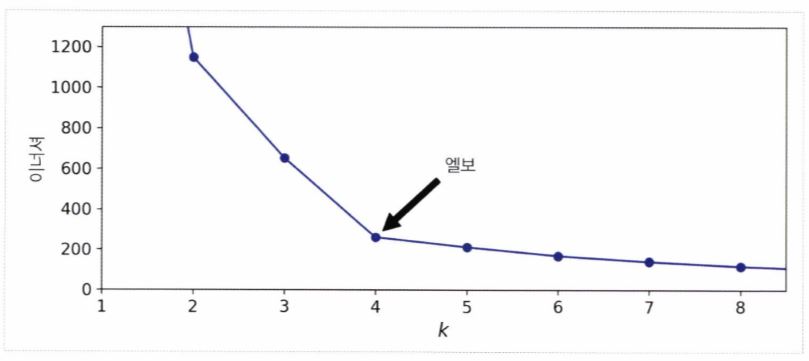
1. 이너셔 그래프를 cluster 개수(k)의 함수로 그렸을 때, 그래프가 꺽이는 지점(Elbow) 찾기
- 아래 그래프를 보면, k가 4까지 증가할 때 이너셔는 빠르게 감소한다.
- 하지만 k가 계속 증가할수록 이너셔의 감소 폭은 크게 줄어드는 것을 알 수 있다.
- 따라서 이 그래프가 꺽이는 지점. 즉, Elbow가 위치한 k 값을 최적의 cluster 개수로 지정해주면 된다.
2. 실루엣 점수 및 실루엣 다이어그램
- 물론 위의 Elbow 방법도 많이 사용하지만, 다소 주먹구구 식이라는 느낌이 든다.
- 그리하여 나온 방법이 바로 "실루엣 점수"이다.
- 이 값은 모든 샘플에 대한 실루엣 계수의 평균 값이다.
- 샘플의 실루엣 계수는 "(b - a) / max(a, b)" 로 계산된다.
- a : 동일한 cluster에 있는 다른 샘플까지의 평균 거리 (즉, cluster 내부의 평균 거리)
- b : 가장 가까운 cluster까지의 평균 거리 (즉, 가장 가까운 cluster의 샘플까지 평균 거리)
- 실루엣 계수는 -1에서 +1까지의 값을 가진다.
- "+1"에 가까운 경우 : 해당 샘플이 cluster 안에 잘 속해 있고, 다른 cluster와는 멀리 떨어져 있다는 의미
- "0"에 가까운 경우 : Cluster 경계에 위치한다는 의미
- "-1"에 가까운 경우 : 해당 샘플이 잘못된 cluster에 할당되었다는 의미
- 실루엣 점수를 계산하려면 사이킷런의 silhouette_score( ) 함수를 사용하면 된다.


- 실루엣 점수와 더불어, 실루엣 다이어그램을 그려보면 더 많은 정보를 얻을 수 있다.
- 각 cluster마다 칼 모양의 그래프가 그려진다.
- 칼 모양 그래프의 높이 : Cluster가 포함하고 있는 샘플의 개수
- 칼 모양 그래프의 너비 : Cluster에 포함된 샘플의 정렬된 실루엣 계수 (따라서 넓을수록 좋음)
- 수직 파선 : 각 cluster 개수에 해당하는 실루엣 점수

<K-means 알고리즘의 한계>
- K-means 알고리즘은 속도가 빠르고 확장이 용이하다는 장점을 갖고 있다.
- 하지만 최적의 cluster 개수(k)를 직접 지정해줘야 한다는 점, 그리고 최적의 솔루션에 도달하지 못하는 문제를 해결하기 위해 알고리즘을 여러 번 실행해주어야 한다는 점이 꽤나 번거롭다.
- 또한 k-means 알고리즘은 cluster의 크기나 밀집도가 서로 다르거나, 원형이 아닐 경우(타원형 등과 같은 경우) 잘 작동하지 않는다.
- 참고로 타원형 cluster에서는 가우시안 혼합 모델(GMM)이 잘 작동한다.
- 마지막으로 k-means 알고리즘을 실행하기 전에 입력 특성의 스케일을 맞춰주는 것은 굉장히 중요하다.
◆ DBSCAN
- 밀도 기반 군집화의 대표적인 알고리즘이다.
- <장점>
- 데이터의 분포가 기하학적으로 복잡한 데이터 셋에도 효과적인 군집화가 가능하다.
- 즉, cluster의 모양과 개수에 상관없이 감지할 수 있는 능력이 뛰어나다.
- 따라서 이상치에 안정적이다.
- 사전에 cluster 개수를 지정할 필요가 없다.
- 데이터의 분포가 기하학적으로 복잡한 데이터 셋에도 효과적인 군집화가 가능하다.
- <단점>
- 데이터 밀도가 자주 변하거나, 아예 모든 데이터의 밀도가 크게 변하지 않으면 성능이 떨어진다.
- 특성(feature)의 개수가 많으면 성능이 떨어진다.
- 새로운 샘플에 대해 cluster를 예측할 수 없다.
- 따라서 사용자가 필요한 예측기를 선택해야 한다.
- DBSCAN의 작동 원리에 대한 자세한 설명은 "파이썬 머신러닝 완벽 가이드" 교재를 참고하면 좋다!!
- "핸즈온 머신러닝 2/E" 교재보다 설명이 자세하게 나와있다...
- DBSCAN을 구성하는 가장 중요한 두 가지 파라미터는 다음과 같다.
- 입실론 주변 영역(epsilon) : 개별 데이터를 중심으로 입실론 반경을 가지는 원형의 영역
- 사이킷런의 eps 파라미터
- 최소 데이터 개수(min points) : 개별 데이터의 입실론 주변 영역에 포함되는 타 데이터의 개수
- 사이킷런의 min_samples 파라미터
- 위 두 개의 파라미터를 통해 최적의 군집을 찾는 게 중요하다.
- 입실론 주변 영역(epsilon) : 개별 데이터를 중심으로 입실론 반경을 가지는 원형의 영역
◆ 다른 군집 알고리즘
1. 병합 군집
2. BIRCH
3. Mean-Shift (평균-이동)→ 주로 "영상 처리" 분야에서 사용함. 자세한 내용은 "파이썬 머신러닝 완벽 가이드" 참고!
4. 유사도 전파
5. 스펙트럼 군집
▶ 가우시안 혼합 모델(GMM)
- 군집화를 적용하고자 하는 데이터가 여러 개의 가우시안 분포(정규분포)를 가진 데이터 집합들이 섞여서 생성된 것이라는 가정 하에 군집화를 수행하는 방식이다.
- 하나의 가우시안 분포에서 생성된 모든 샘플은 하나의 cluster를 형성한다.
- 일반적으로 이 cluster는 타원형이다.
- K-means 알고리즘의 단점을 보완해줄 수 있는 모델이다.
- GMM은 k-means보다 유연하게 다양한 데이터 셋에 잘 적용될 수 있다. (그러나 수행 시간이 오래 걸림)
- 이상치 탐지에도 사용할 수 있다.
- 사이킷런의 GaussianMixture 클래스를 사용해서 구현이 가능하다.
- 단, GMM의 경우 cluster 개수(k)를 지정해주어야 한다.
- 그렇다면 cluster의 개수(k)를 어떻게 지정해주면 좋을까? (즉, GMM의 성능 지표는 무엇일까?)
- → AIC, BIC와 같은 이론적 정보 기준을 최소화 하는 모델을 선택!!

위 식을 이해하려면 MLE에 대한 개념이 필요한데, 이번 포스팅에서는 따로 설명하지 않도록 하겠다.
(수리통계학에 대한 내용으로 넘어가야 하기 때문에...)
간단하게 말하면 "AIC 및 BIC를 최소화하는 모델을 선택해야 하는데,
그러려면 가능도 함수를 최대화해야 되겠구나!!" 정도로만 이해하고 넘어가도록 하자.
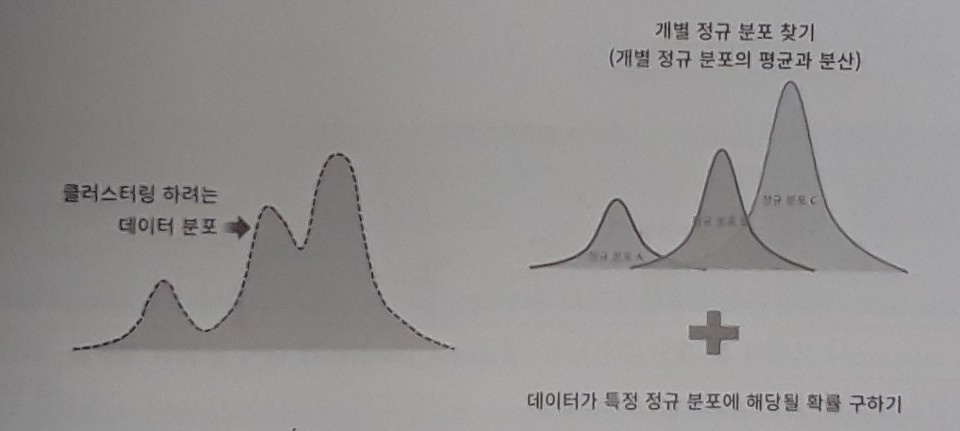
<EM(기댓값-최대화) 알고리즘>
- GMM의 모수를 추정하기 위해 사용하는 알고리즘이다.
- 여기서 말하는 모수 추정은 대표적으로 다음의 2가지를 추정하는 것이다.
- 개별 정규 분포의 평균과 분산
- 각 데이터가 어떤 정규분포에 해당되는지의 확률
- 여기서 말하는 모수 추정은 대표적으로 다음의 2가지를 추정하는 것이다.
<Step 1> Expectation
- 개별 데이터 각각에 대해서 특정 정규 분포에 소속될 확률을 구하고, 가장 높은 확률을 가진 정규분포에 소속시킨다.
- 최초 시에는 데이터들을 임의로 특정 정규분포로 소속시킨다.
<Step 2> Maximization
- 데이터들이 특정 정규분포로 소속되면, 다시 해당 정규분포의 평균(모수)과 분산(모수)을 구한다.
- 해당 데이터가 발견될 수 있는 가능도(likelihood)를 최대화할 수 있도록 평균(모수)과 분산(모수)을 구한다.
- 여기서 MLE 개념이 나오네...(즐거웠던 "수리통계학" 강의 시간이 떠오르네 ㅎ)
<Step 3>
- 개별 정규분포의 모수인 평균과 분산이 더 이상 변경되지 않고, 각 개별 데이터들의 이전 정규분포 소속이 더 이상 변경되지 않으면, 그것으로 최종 군집화를 결정한다.
- 그렇지 않으면 계속 EM 반복을 수행한다.
▶ 이상치 탐지와 특이치 탐지를 위한 다른 알고리즘
- PCA → 이상치 탐지 기법
- Fast-MCD → 이상치 탐지 기법
- 아이솔레이션 포레스트 → 이상치 탐지 기법
- LOF(Local Outlier Factor) → 이상치 탐지 기법
- One-class SVM → 특이치 탐지 기법
<참고>
- 교재에는 "베이즈 가우시안 혼합 모델"에 대한 내용도 나와있었으나, 내용이 너무 어렵고 이해도 잘 되지 않아서 일단 이번 포스팅에서는 다루지 않았다.
이번 "9장. 비지도 학습"을 끝으로, "핸즈온 머신러닝 2/E" 교재 Part 1(머신러닝 파트)에 대한 포스팅을 모두 마치도록 하겠다.
"핸즈온 머신러닝 2/E 교재 Part 2(딥러닝 파트)"는 딥러닝에 대한 기초를 갈고 닦은 후에 공부할 예정이다.
★ 참고 자료
- 핸즈온 머신러닝 2/E 교재
- 파이썬 머신러닝 완벽 가이드 교재
'Data Science > Machine Learning' 카테고리의 다른 글
| 베이지안 최적화(Bayesian Optimization) (4) | 2021.02.05 |
|---|---|
| [핸즈온 머신러닝 2/E] 8장. 차원 축소 (0) | 2020.07.29 |
| [핸즈온 머신러닝 2/E] 7장. 앙상블 학습과 랜덤 포레스트 (0) | 2020.07.27 |
| [핸즈온 머신러닝 2/E] 6장. 결정 트리 (6) | 2020.07.18 |
| [핸즈온 머신러닝 2/E] 5장. 서포트 벡터 머신 (0) | 2020.07.08 |



